Goal
그래프의 기본 개념 이해
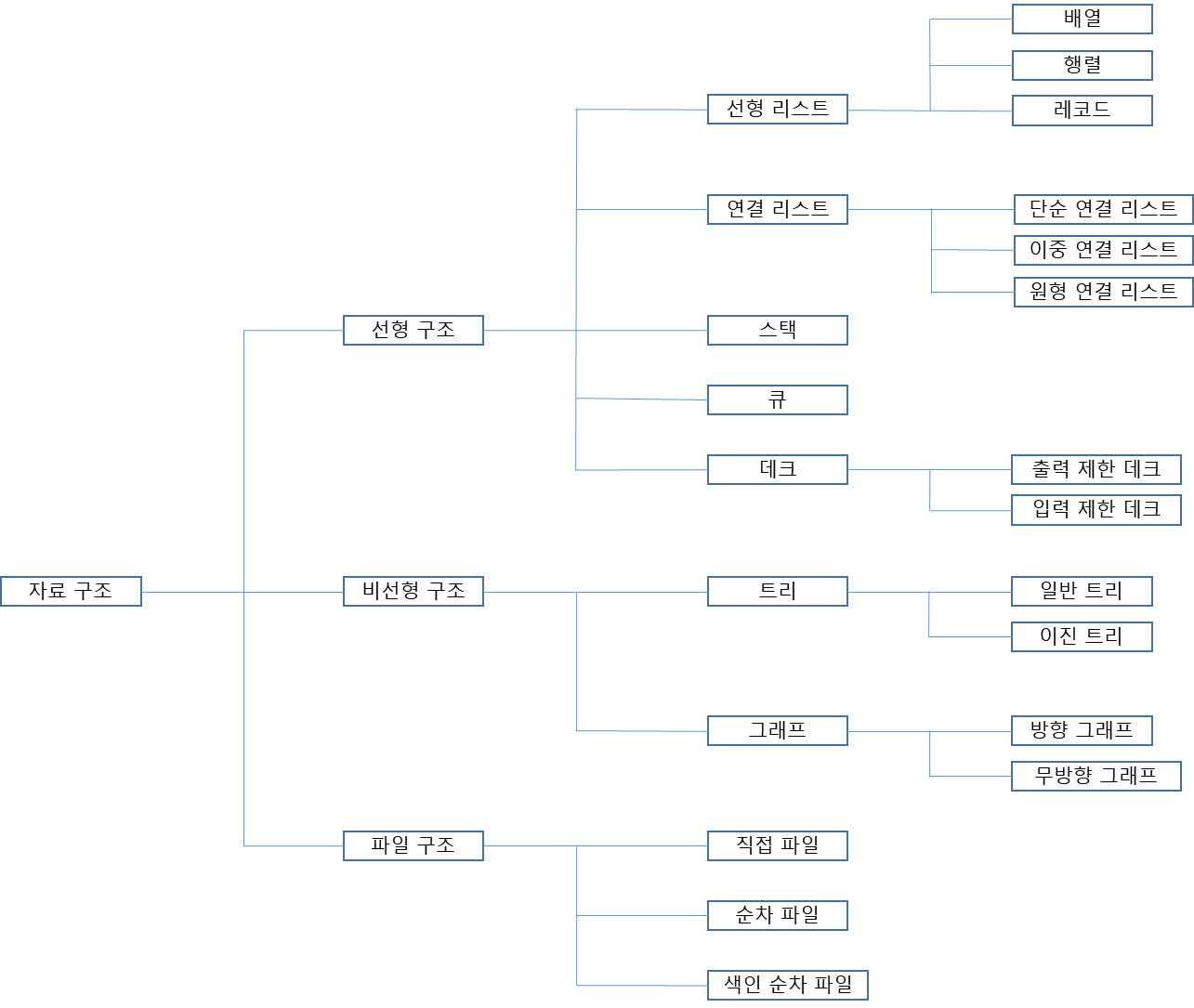
2021.12.16 - [자료구조] - [자료 구조] 자료 구조에 대한 이해
[자료 구조] 자료 구조에 대한 이해
Goal 자료 구조란 무엇인가 자료 구조를 왜 알아야 하는가 어떠한 자료 구조가 있는가 자료 구조 선택 시 고려할 점 자료 구조(Data Structure)란? 1) 자료 구조의 개념 자료 구조(Data Structure)란, 실세계
ongveloper.tistory.com
0. 둘 다 그게 그거 아니야?
결론부터 말하자면 Array는 메모리 상에 데이터가 연속적으로 저장되고,
List는 메모리 상에 데이터가 비연속적으로 저장된다.
(Array와 List의 차이를 묻는 것은 Array와 LinkedList의 차이를 묻는 것이 일반적이다.)
Array와 List 모두 선형 자료구조로 동일한 용도로 사용하기에, 둘의 차이를 모르고 사용하는 경우가 많을 것이다.
하지만 우리가 자료 구조를 공부하는 이유는 프로그래밍에 있어 어떠한 문제를 해결할 때, 어떠한 자료를 표현하기 위해 적절한 자료 구조를 사용하여 프로그램의 성능을 높이기 위함이다.
굉장히 유사한 두 자료 구조의 차이를 알아보자.
선형 자료 구조 : 원소들을 순서대로 나열한 집합
순차 리스트 : 원소들이 실제 메모리 상 시작 위치부터 끝 위치까지 순차적으로 저장된 것
1. Array(배열)
1) Array(배열)이란?
우선 배열이란 같은 성질을 갖는 항목들의 집합이다.
같은 특성을 갖는 원소들이 순서대로 구성된 집합으로 선형 자료 구조이며,
메모리 상에 연속적으로 데이터가 저장된 연접 리스트(순차 리스트)에 해당한다.
순차적으로 저장된 데이터를 참조하는 데에는 Index가 사용된다.
(1차원 배열, 2차원 배열, 3차원 배열, )

2) Array(배열)의 특징
- 고정된 크기를 갖는다.(데이터의 개수가 정해져 있다.)
- 배열의 크기를 10으로 지정한다면, 내부에 데이터가 5개만 있더라도 실제 배열의 크기는 10이다.
-> 메모리가 낭비될 수 있다.
- 배열의 크기를 10으로 지정한다면, 내부에 데이터가 5개만 있더라도 실제 배열의 크기는 10이다.
- 논리적 저장 순서와 물리적 저장 순서가 일치하다. (메모리 상에 데이터도 순차적으로 저장된다.)
- Cache Hit Rate 가 높다.
- 추가적으로 소모되는 메모리 양(오버헤드)이 거의 없다. (데이터의 양에 맞게 크기를 정해놓고 사용하기 때문)
- 삽입과 삭제의 경우 O(N)의 시간 복잡도를 갖는다.
- 원소에 접근할 때는 O(1)의 시간 복잡도를 갖는다.
- 기억 장소를 미리 확보해야 한다.
3) Cache Hit Rate?
Cache Hit이란 CPU가 참조하고자 하는 메모리가 캐시에 존재하고 있는 경우를 말한다.
이 비율이 높을수록 좋은 성능을 가질 수 있다.
우선 메모리에 대한 개념 중 참조 지역성 원리라는 것이 있다.
참조 지역성 원리란 동일한 값 또는 해당 값에 관계된 스토리지 위치가 자주 액세스되는 특성으로, 지역성의 원리(Principle of Locality)라고도 부른다.
이 참조 지역성에는 3가지 종류가 있다.
1. 공간 지역성(Spacial Locality) : 참조된 주소와 인접한 주소의 내용이 다시 참조되는 특성
2. 시간 지역성(Temporal Locality) : 최근에 참조된 주소는 빠른 시간 내에 다시 참조되는 특성
3. 순차 지역성(Sequential Locality) : 데이터가 순차적으로 액세스 되는 특성, 공간 지역성에 편입되어 설명되기도 함
배열은 메모리 상 연속적으로 데이터가 저장되어있다고 했다.
즉, 배열은 공간 지역성이 좋아 높은 Cache Hit Rate를 가진다고 할 수 있다.
4) Array(배열)의 연산
1. 원소 확인 및 변경
위의 배열에서 인덱스 3에 있는 7이란 데이터를 8로 변경한다고 하자.
인덱스 3을 찾는 방법은, 배열은 메모리 상에 일렬로 나열되어 있으니 배열의 시작 주소인 인덱스 0에서 3번째 칸을 찾으면 된다. 이는 시작 주소+ 3으로 O(1)만에 찾고, 변경할 수 있다.

2. 원소 삽입 및 삭제
위의 배열에서 인덱스 3에 있는 7이란 데이터를 삭제한다고 하자.
인덱스 3에 있는 데이터를 삭제하여도, 배열은 메모리 상에 일렬로 나열되어있고, 크기는 고정되어있다는 특징을 가지기 때문에 인덱스 3은 그대로 있고 우측에 데이터들이 한 칸씩 땡겨진다.


인덱스 3 뒤에 있는 3 개의 원소를 한 칸씩 땡겨야 한다.
만약 인덱스 0의 데이터를 삭제한다고 하면, 6개의 원소를 땡겨야 하고,
인덱스 6의 데이터를 삭제한다고 하면 0개의 원소를 땡긴다.
평균적으로 어떠한 원소를 삭제할 때 N(배열의 크기)/2만큼 땡겨야 하므로 삭제의 시간 복잡도는 O(N)이 되며,
삭제 연산을 위한 함수가 없으니 직접 구현해야 한다.
삽입도 마찬가지 O(N)이다.
크기가 10인 배열에 7개의 데이터가 들어가 있다고 하자.
인덱스 3 위치에 데이터 19를 추가한다고 하면, 인덱스 3 우측에 있는 데이터들이 한 칸씩 우측으로 밀려난다.
이 또한 직접 구현해야 한다.


위의 배열에서 배열의 전체 크기와 실제 데이터가 저장된 개수가 다르다.
데이터가 저장된 개수를 길이라 하고, 배열의 전체 크기(N)를 크기라 했을 때, 길이는 7 크기는 10이라 할 수 있다.
삽입과 삭제의 평균 연산 횟수를 N/2라고 했는데, 사실 인덱스 3의 위치에 삽입, 삭제를 한다면 "길이인 7 빼기 현재 인덱스 3의 순서 4를 빼서 뒤에 있는 3개만 땡기거나 밀면 되는 거 아니야? 7,8,9 인덱스에는 데이터 없잖아."라고 생각할 수 있다. 뒤에 7, 8, 9인덱스에 데이터가 있는지 없는지는 조상님이 알려주지 않는다.
즉 7, 8, 9에 데이터가 있는지 없는지 확인은 해야 하기 때문에 결국 길이가 아닌 크기로 계산하는 것이다.
이러한 삽입, 삭제를 직접 구현해야 한다고 했는데, 바킹독님의 자료를 보고 구현하자.
2. List(리스트)
1) List(리스트)란?
자료 구조의 관점으로 보면 배열 또한 리스트에 포함되지만, 프로그래밍 언어의 관점으로 리스트란 배열이 가지고 있는 인덱스라는 장점을 버리고, 빈틈없는 데이터의 적재라는 장점을 취한 인터페이스다.
즉, Linked List(연결 리스트), ArrayList 등의 선형 자료 구조를 구현할 때 사용되는 추상 자료형이다.
같은 특성을 갖는 원소들이 순서대로 구성된 집합인 선형 자료 구조이다.
하지만 데이터가 메모리 상에 연속적으로 저장되진 않기 때문에 순차 리스트가 아닌 연결 리스트라 불린다.
맨 위에 자료 구조의 형태에 따른 분류 사진에 리스트가 없는 것은 실제 자료 구조 관점과, 프로그래밍 언어의 관점에서의 차이라 할 수 있다.
배열의 문제점을 해결하기 위한 자료 구조라 할 수 있고, 시퀀스(Sequence)라고도 부른다.
(시퀀스라 부르는 건 거의 못 봤다.)
보통 Array(배열)과 List(리스트)의 차이를 묻는 것은, "리스트는 선형 자료 구조를 구현할 때 사용되는 인터페이스다"라고 하기보단, 리스트를 LinkedList(연결 리스트)처럼 모습이 확정된 자료 구조라고 생각하고 대답하는 것을 요구한다.
2) List(리스트)의 특징 (LinkedList)
- 배열은 크기가 정해져 있고, 메모리 상에 데이터가 연속적으로 있어야 하기 때문에 메모리의 낭비가 발생할 수 있다.
하지만 리스트는 빈 공간을 허용하지 않기 때문에 이러한 메모리의 낭비는 없다. - 데이터들이 순차적으로 구성된 집합이지만, 일반적으로 데이터가 메모리 상에 연속적으로 있진 않다.
(실제 메모리 주소 랜덤) - 따라서 Cache Hit Rate가 낮다.
- 크기가 가변적이다.
- 원소에 접근할 때 O(N)의 시간 복잡도를 갖는다.
- 삽입과 삭제의 경우 O(N)의 시간 복잡도를 갖는다.
- 삽입, 삭제, 크기 등 해당 리스트를 사용하기 위한 다양한 속성과 메서드가 존재한다.
(기본 동작은 구현할 필요 없다.)
3) List(리스트)의 연산
List(리스트)의 일반적인 모습인 Linked List(연결 리스트) 기반으로 설명하겠다.
(연결 리스트에도 단일 연결 리스트, 이중 연결 리스트, 원형 연결 리스트가 있고, 아래의 모습은 단일 연결 리스트이다.)
연결 리스트란 각 원소가 자신의 다음 원소의 주소를 저장하고 있는 연결 리스트이다.
(리스트의 크기를 N이라 하자.)

1. 원소 확인 및 변경
'소'를 '닭'으로 바꾼다고 하자.
순차 접근 방식을 사용하기 때문에 처음부터 순차적으로 탐색해서 '소'를 찾아야만 한다.
이렇게 '소'가 있는 곳을 찾는 데에 평균적으로 O(N)의 시간 복잡도를 가지며, '소'를 '닭'으로 변경하는 동작 자체는 O(1)의 시간 복잡도를 갖는다.
결과적으로 O(N)의 시간 복잡도로 '소'의 데이터를 확인 및 변경할 수 있는 것이다.

2. 원소 삽입 및 삭제
'소'를 삭제한다고 하자.
마찬가지로 '쥐'부터 해서 '소'를 찾아가야 하는데 O(N)의 시간 복잡도를 갖는다.
이후, '소'를 삭제하면 '개'가 가리킬 다음 주소를 '양'의 주소로만 바꾸어주면 되기 때문에 이 동작은 O(1)이다.
결과적으로 O(N)의 시간 복잡도를 갖는다.
또한, 리스트의 크기가 5에서 4로 줄었다.(크기가 가변적이다.)

'양'과 '말' 사이에 '뱀'을 추가한다고 하자.
마찬가지로 '쥐'부터 해서 '양'을 찾아가야 하는데 O(N)의 시간 복잡도를 갖는다.
이후, '양'이 가리킬 다음 주소에 어느 메모리에 새롭게 저장된 '뱀'의 주소를 저장하고, '뱀'은 다음 주소인 '말'을 가리킨다. 이 동작도 O(1)이다.
결과적으로 O(N)의 시간 복잡도를 갖는다.
또한, 리스트의 크기가 5에서 6으로 늘었다.(크기가 가변적이다.)

4) 메모리 상에 연속적이지 않다?
Int 형 자료가 배열 혹은 리스트로 저장되어 있다고 하자.
Int는 4Byte이므로
배열의 각 원소의 주소는
100 104 108 112
연속적인 모습을 볼 수 있다.
반면 리스트의 경우
100 204 308 412
즉, 바로 다음 공간에 있지 않고 띄엄띄엄 있는 모습을 생각하면 되고, 이것이 비 연속적이라는 것이다.
5) ArrayList vs LinkedList


Java docs에 따르면 Java엔 ArrayList라는 자료 구조가 있다.
위의 자료를 보면 List 기반 자료 구조인 것을 알 수 있는데,
이 ArrayList가 뭔지 알아보자.
Java의 Collection에 속한 ArrayList는 내부적으로 Array(배열)로 이루어져 있다.
즉, List의 특징과 Array의 특징을 섞어서 가지고 있는 자료 구조이다.
크기가 가변적인 배열이라고 생각하는 것이 직관적이다.
내부적으로 배열로 이루어져 있기 때문에 이 ArrayList도 인덱스를 가지고, 원소들이 순서대로 저장되는 선형 자료 구조이며, 데이터가 메모리 상에 연속적으로 저장되는 순차 리스트이다.
따라서, ArrayList도 데이터를 확인하고 변경하는 작업은 O(1)의 시간 복잡도를 가진다.
Collection에 속한 ArrayList도 당연히 여러 속성과 메서드를 사용할 수 있다.
데이터를 추가하는 add 연산의 경우 데이터를 끝에 추가하는 것과 중간에 추가하는 것으로 나뉘는데,
내부적으론 더 많은 내용이 있지만, 데이터를 끝에 추가하는 경우는 O(1), 중간에 추가하는 경우 이후의 데이터들을 한 칸씩 밀어야 하므로 O(N)의 시간 복잡도를 갖는다는 정도만 얘기하자.
ArrayList에서 이렇게 데이터를 끝에 추가하는 경우, 중간에 추가하는 경우를 나누는 이유는
ArrayList는 크기가 가변적인 동적 리스트로써 데이터를 끝에 추가하는 연산을 많이 사용하기 때문이다.
하지만 데이터를 끝에 추가하는 경우 Array와 다르게, ArrayList의 크기를 키운 후 새로운 공간에 더 큰 메모리를 잡은 후
기존의 ArrayList의 요소를 복사하고 원소를 추가한다. 애초에 Array에서 데이터를 끝에 추가한다고 해봐야, 기존 Array의 크기는 10인데 데이터가 5개만 들어있을 경우 한 개를 추가해서 6개가 되는 경우를 말한다.
따라서 평균적으로 데이터를 추가하는 경우가 Array보다 느리다. (이를 방지하기 위해 ArrayList도 크기를 정해놓고 사용하곤 한다. 예를 들면 집합의 크기가 상수가 아닌 변수인 경우)
데이터를 삭제하는 remove 연산의 경우 데이터를 땡겨야 하므로 O(N)의 시간 복잡도를 갖는다.
이외에 ArrayList와 비슷한 Vector 자료 구조도 있는데, Vector는 예전 자바에서 제공한 레거시 클래스로, 멀티 스레드 환경에서 사용한다. 즉, 멀티 스레드 환경이 아니거나 Vector를 사용하란 명시가 없는 경우 ArrayList를 사용한다.
3. Array vs ArrayList vs LinkedList

- 크기가 가변적인 배열이 필요하다면 ArrayList
- LinkedList의 삭제, 추가 시간 복잡도는 O(N)이지만 Array나 ArrayList보다 빠름
- 데이터의 삭제 추가가 많을 때 -> LinkedList
- 데이터의 접근이 많을 때 -> Array, ArrayList
- Array, ArrayList는 인덱스가 있지만 LinkedList는 없다.
- 인덱스가 필요하면 Array, ArrayList
- 인덱스가 필요 없다면 LinkedList
수정
ArrayList는 아래 링크를 참조하면 실제 개체는 연속된 위치에 저장되지 않고 실제 개체의 참조는 인접한 위치에 저장된다고 합니다.
따라서 ArrayList를 순차 리스트라고 보기는 어려울 것 같습니다.
https://www.geeksforgeeks.org/array-vs-arraylist-in-java/
4. References
https://blog.encrypted.gg/927?category=773649
https://choheeis.github.io/newblog//articles/2020-12/data-structure-array
https://docs.oracle.com/javase/8/docs/api/java/util/ArrayList.html
https://docs.oracle.com/javase/8/docs/api/java/util/List.html
자료구조(정일)-이경훈,최명세,이윤수 공저
TODO
Java ArrayList vs Vector
'자료구조' 카테고리의 다른 글
| [자료구조] 자료구조에 대한 이해 (1) | 2021.12.16 |
|---|---|
| [자료구조] 그래프(Graph)란? (2) | 2021.07.29 |


댓글